Date: 2024-07-22
Problem
- Based on the input
charactersanddocumentwhich are both strings, we need to determine whether we can generate the word in document based on the characters in the characters string. This mean you should have the same or more of the characters apparent in the document string - Notes
- Spaces or underscores can be considered spaces and required to take into account if its in the document string. without it we can’t replicate the document string
- can be letters, uppercase, special characters. can be anything
Solution
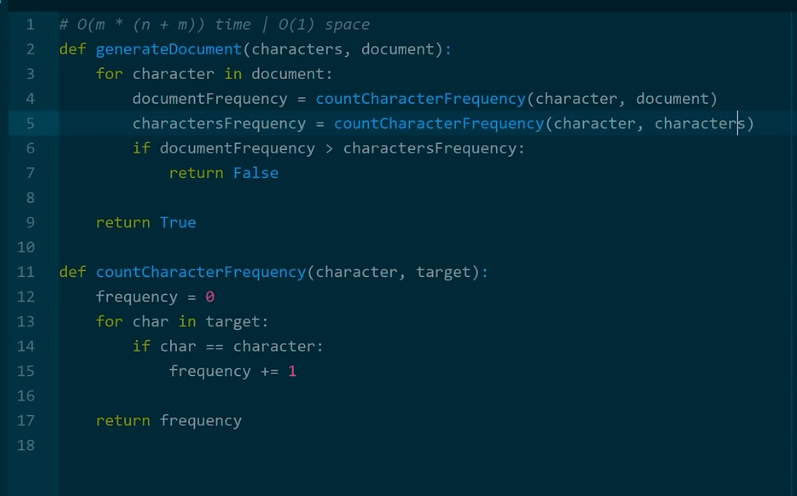
Solution 1: Non optimal solutIon:
- Start off with document string, go through each one counting how many times a character appears in the document string and that it should be the same in the characters string. This is non optimal because if we reach a character that we already counted initially well count again if we reach it again in the document string.
- Therefore, this results in a (M (n+m)) time. This is because we are iterating through characters and document for each iteration (n+m) and then doing that M times (M) resulting in (M * (n+m))
- The space complexity is the constant because we are not using any new space
 Solution 2: Also Non optimal
Solution 2: Also Non optimal - This solution is very similar to the last one, however, this time after counting a character initially we add that letter to a set to keep track of a character we already counted and verified, so that we can skip it.
- Time complexity is the almost same however, since we cut down on counting duplicated characters we can add
countedto our time complexity: O(c * (n+m))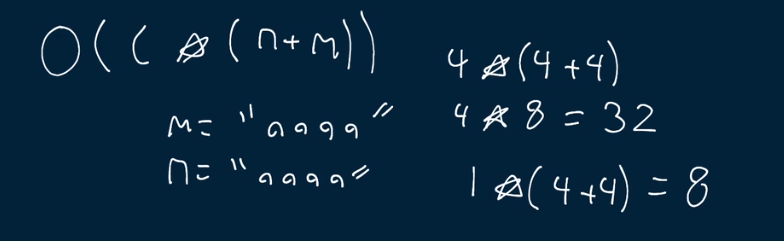
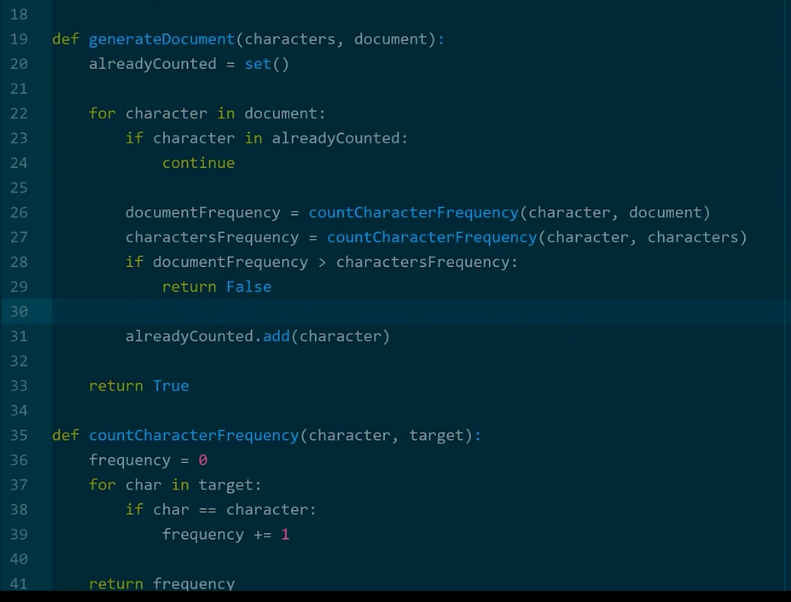
Solution 3: Optimal Solution
- Instead of looping through the document and characters multiple times we can loop through them once and have a parent counter to keep track if we have enough characters to replicate document.
- To accomplish we can use a hashmap aka dictionary
{char: 3}
- First we will loop through the characters string and initiate and keep count of all the characters that occur in that string.
- Next, we have to count the characters in document but the way well do this is by simply subtracting one for each occurrence counted in document. this is essentially the same as have a stock of 10 apples and as we go through the iteration of what we need we subtract one from the stock. if we ever get to zero and still need more, then we know we don’t have enough.
- Therefore if the value of a key reaches 0 or is not even available from the hashmap then we know that we can recreate the document string.
- Time: O(n+m) we removed the multiple iterations and just need one iteration of both strings. Space: is O(c) is the characters string since we are iterating of the characters strings and the worst possible space complexity is O(c).
def generateDocument(characters, document):
# Hash map
characterCounts = {}
# Loop through characters string
for character in characters:
# if character is not in hashmap intiaite it
if character not in characterCounts:
characterCounts[character] = 0
# Keep adding to the count if character has already been intiated
characterCounts[character] += 1
# Start substracting from our available characters
for character in document:
# if the character does not exist in our hashmap or we have
# no more characters available for the current iteration
# return False
if character not in characterCounts or characterCounts[character] == 0:
return False
# Otherwise, keep decrementing.
characterCounts[character] -= 1
# If we made it all the way through then we had enough
return True