Traffic Light RL
| Topics: Sumo, Ray, and Reinforcement learning |
![]()
Project Overview
In this project, we’ll teach an AI to control traffic signals using reinforcement learning (RL) in a simulated traffic environment. By interacting with the traffic network, the AI will learn how to optimize traffic flow by controlling the signals, improving efficiency and reducing vehicle waiting time. We’ll be using tools like Ray, SUMO, and SUMO-RL to build and train our model.
Reinforcement learning is a powerful technique for training AI agents by letting them learn from trial and error in dynamic environments. This project will introduce key concepts of reinforcement learning and show how they can be applied to real-world problems, such as optimizing traffic light schedules to reduce congestion.
For scenarios where multiple traffic lights need to be controlled, we will extend the model into a multi-agent system. Each traffic signal will act as an independent agent, working either collaboratively or independently to manage traffic in different parts of the network. This multi-agent approach is necessary when dealing with larger networks where multiple intersections must be optimized simultaneously.
Objectives
- Set up the traffic simulation environment using SUMO and SUMO-RL.
- Train an AI model to control traffic lights using Proximal Policy Optimization (PPO), a popular RL algorithm.
- Extend the system to handle multiple traffic lights by creating a multi-agent setup, where each signal acts as an independent RL agent.
- Evaluate the performance of the model as it interacts with the traffic environment and measures improvements in traffic flow.
Prerequisites
Before continuing, ensure the following are installed:
Technology Overview
-
SUMO (Simulation of Urban MObility)
- Purpose: A traffic simulation tool used to model and analyze urban mobility.
- Usage: Essential for simulating traffic flows in our RL project, where traffic lights act as agents to reduce congestion. SUMO provides a realistic environment for testing traffic signal control systems.
-
SUMO-RL
- Purpose: Provides an interface for implementing reinforcement learning on SUMO’s traffic signal control simulations.
- Usage: Allows our RL model to control traffic lights as agents in a multi-agent environment, using frameworks like Gymnasium and PettingZoo for agent interaction. It supports defining custom state and reward structures, making it ideal for experiments in traffic optimization.
-
PyTorch
- Purpose: A deep learning framework commonly used to create and train neural networks.
- Usage: Enables the development of reinforcement learning algorithms that our agents (traffic lights) use to optimize traffic flow. PyTorch provides the flexibility needed for designing multi-agent models, making it essential for training and evaluating our traffic control system.
Setting up SUMO Environment
Objective
- Set up the SUMO environment to simulate a multi-intersection traffic grid for reinforcement learning (RL).
Step-by-Step Explanation
Before we can train our RL agents, we need to set up the traffic simulation environment using SUMO and SUMO-RL. This involves defining the layout of the road network, the traffic routes, and integrating SUMO with our RL environment.
-
To accomplish the following, you don’t need to it manually through code but rather through the gui and export the necessary XML’s
-
Create Traffic Network
Use SUMO’s.net.xmlfile format to define the road layout. This includes the number of lanes, intersections, and traffic lights. For example, you can create a 2x2 or 4x4 grid, representing multiple intersections that the AI will control. -
Route File
The.rou.xmlfile defines the vehicle routes, which specify how cars move through the network. It’s important for simulating real-world traffic conditions. -
Configure SUMO-RL
SUMO-RL provides an interface for connecting SUMO with reinforcement learning. We’ll use it to load the traffic network and route files into the RL environment, enabling the agents to interact with the simulation.
Outcome
At this stage, your SUMO traffic simulation environment is set up, and it is ready to be used by the RL agents for training and optimizing traffic signals.
⭕ Make sure to add your network and route xml files and adjust the paths if they differ.⭕ If you're PC isn't that advanced hardware wise you can reduce the `num_seconds` to something smaller. This will reduce the episode length and strain on the cpu/gpu
# --- SETTING UP THE SUMO ENVIRONMENT ---
# Import necessary libraries
import sumo_rl
# Simple environment setup (no multi-agent logic yet)
sumo_env = sumo_rl.parallel_env(
net_file = 'data/miami.net.xml',
route_file = 'data/miami.rou.xml',
out_csv_name = 'outputs/miami.csv',
use_gui = False,
num_seconds = 80000,
)Step-by-Step Explanation
-
Import Libraries:
- We import the
sumo_rllibrary, which handles the necessary steps to process our environment for reinforcement learning. It takes in our network and route xml file and by default defines our observation, action, and reward functions.
- We import the
-
Environment Setup:
- This environment is based off the area on the map we defined using
osmWebWizardwhich allowed us to convert the area into SUMO compatible files.
- This environment is based off the area on the map we defined using
-
Network and Route Files:
- The
net_filedefines the road layout, and theroute_filespecifies how vehicles move through the network.
- The
-
Output CSV:
- The
out_csv_nameparameter specifies the file where traffic data (like waiting times) will be saved for analysis.
- The
-
Simulation Settings:
use_gui=Falsedisables the graphical interface.num_seconds=80000sets the duration of the simulation in seconds.
Outcome
- After running this code, the basic SUMO environment is ready to simulate traffic, although reinforcement learning is not yet integrated.
Define Multi-Agent RL Environment
Objective
- Set up the multi-agent RL environment where each traffic light acts as an independent agent
- Deifne the observation, action, and reward spaces for training.
Step-by-Step Explanation
Since we are controlling multiple traffic lights, we need to define a multi-agent environment in SUMO-RL where each traffic signal operates independently, learning how to manage traffic flow efficiently.
-
Why multi-agent?
Each traffic signal operates in its own space, so a multi-agent setup allows each signal to learn independently but cooperatively manage traffic across intersections. -
Observation Space
The observation space is already predefined in the SUMO-RL library, but it’s important to understand the information the agents receive from the environment. -
Action Space
The action space is also predefined, allowing agents to choose between different phase configurations. However, it’s important to define which actions are available to each agent and how often they can make decisions. -
Reward Function
The reward function defines how the agent is rewarded or penalized based on its actions. By default, the reward is based on total delay or waiting time of vehicles. You may want to define a custom reward function depending on the traffic optimization goal, such as reducing queue lengths or minimizing total delay.
Outcome
After configuring the multi-agent environment, each traffic signal is now an independent RL agent, ready to learn from its environment and optimize traffic flow.
⭕ If you ran ray already make sure to shutdown the ray instance to avoid errors.import ray
ray.shutdown()# --- SETTING UP MULTI-AGENT RL ENVIRONMENT ---
# Import necessary libraries for multi-agent RL
from ray.tune.registry import register_env
from ray.rllib.env.wrappers.pettingzoo_env import ParallelPettingZooEnv
# Register the multi-agent environment
env_name = "miami-grid"
register_env(env_name, lambda _: ParallelPettingZooEnv(sumo_env))Step-by-Step Explanation
-
Import Libraries:
- We import the necessary libraries, including
register_envfrom Ray, which allows us to register custom environments for reinforcement learning, andParallelPettingZooEnvto wrap our SUMO environment and enable multi-agent support. - Ray: Ray is a framework for parallel and distributed Python applications, particularly useful for reinforcement learning.
- PettingZoo: PettingZoo is a library designed for multi-agent reinforcement learning (MARL), enabling agents to interact with each other and the environment simultaneously.
- We import the necessary libraries, including
-
Using Predefined SUMO Environment:
- The SUMO environment has already been set up and assigned to the variable
sumo_env. This includes the network layout (net_file) and vehicle routes (route_file), as well as simulation settings likeuse_gui=Falseandnum_seconds=80000.
- The SUMO environment has already been set up and assigned to the variable
-
Register the Multi-Agent Environment:
- We use
register_envto create a new environment named"miami-grid". This environment allows reinforcement learning agents to interact with SUMO, where each agent controls a traffic light at a specific intersection. - The
ParallelPettingZooEnvwrapper is used to handle the multi-agent aspect, allowing all traffic lights (agents) to operate simultaneously.
- We use
Outcome
- After running this code, the SUMO environment is ready for multi-agent reinforcement learning, with each traffic light acting as an independent agent within the simulation.
Implement and Train PPO Algorithm
Objective
- Implement and train the agents using the Proximal Policy Optimization (PPO) algorithm from Ray to optimize traffic signal control.
Step-by-Step Explanation
PPO is a popular reinforcement learning algorithm that works well with complex environments like traffic simulations. We’ll use Ray to implement, configure, and train the PPO algorithm in the multi-agent environment.
-
Why PPO?
PPO is robust and efficient for environments with continuous and discrete action spaces, making it suitable for traffic light control, where the agent’s actions (signal phase changes) can have a large impact on traffic flow. -
Configure PPO
Set up PPO with custom hyperparameters like learning rate, number of timesteps, and discount factor. You’ll also need to define the policy and model architecture based on your environment. Also be sure to setup TensorBoard as this will allow us to track training metrics. -
Integrate PPO with SUMO-RL
Connect the PPO model to the multi-agent environment created in SUMO-RL. The PPO algorithm will use the agents’ observations to update its policy and optimize traffic control. -
Train Model and Track Progress
During training, monitor key metrics available from the observation space, such as lane density, vehicle queue lengths, and traffic signal phases. These metrics will help evaluate the agents’ learning progress and the impact on traffic flow over time. -
Save Model Checkpoints
Periodically save model checkpoints during training to ensure progress is preserved, and to enable future testing or further training. This can be done using a callback function.
Outcome
With the PPO model implemented and training in progress, the traffic signals will gradually learn to manage traffic flow more efficiently, optimizing signal timing to reduce congestion.
Implement
# --- IMPLEMENT AND TRAIN PPO ALGORITHM ---
# Import PPOConfig from Ray's PPO algorithm
from ray.rllib.algorithms.ppo import PPOConfig
import os
# Define PPO configuration
config = (
PPOConfig()
.environment(env=env_name, disable_env_checking=True)
.rollouts(num_rollout_workers=4, rollout_fragment_length=128)
.training(
train_batch_size=512,
lr=2e-5,
gamma=0.95,
lambda_=0.9,
use_gae=True,
clip_param=0.4,
grad_clip=None,
entropy_coeff=0.1,
vf_loss_coeff=0.25,
sgd_minibatch_size=64,
num_sgd_iter=10,
)
.debugging(log_level="ERROR")
.framework(framework="torch")
.resources(num_gpus=int(os.environ.get("RLLIB_NUM_GPUS", "0")))
# If you don't have a GPU, you can set this to 0
# .resources(num_gpus=0)
)Train
⭕ Please adjust `storage_path` to a folder in your project, this is where results from ray will be saved.from ray import tune
tune.run(
"PPO",
name="PPO",
stop={"timesteps_total": 100000},
checkpoint_freq=10,
storage_path="/define/your/path/ray_results/" + env_name,
config=config.to_dict(),
)Step-by-Step Explanation
-
Import PPOConfig:
- We import
PPOConfigfrom Ray’s PPO algorithm. This will allow us to set up the necessary hyperparameters and configurations for training the reinforcement learning agents.
- We import
-
Configure PPO:
- We define the PPO configuration using
.environment()to link it to the registered environment (env_name) and setdisable_env_checking=Trueto bypass environment compatibility checks. - Rollout Settings:
num_rollout_workers=4: Specifies two workers that collect experience during training.rollout_fragment_length=128: Determines how many steps each worker will gather before sending data for training.
- Training Hyperparameters: These settings control how the PPO algorithm updates its policy:
train_batch_size=512: The total number of steps collected from all workers before updating the model.lr=2e-5: The learning rate, which controls how much the model updates with each step.gamma=0.95: The discount factor that controls how much the agent prioritizes future rewards over immediate ones.lambda_=0.9,use_gae=True: Parameters for Generalized Advantage Estimation, used to reduce variance in policy updates.clip_param=0.4: Controls how much the policy can change at each update, preventing overly large updates.entropy_coeff=0.1: Encourages exploration by adding randomness to the agent’s actions.vf_loss_coeff=0.25: The coefficient for the value function loss, which helps the agent evaluate its performance.sgd_minibatch_size=64: Mini-batch size for training.num_sgd_iter=10: Number of optimization steps performed during each update.
- We define the PPO configuration using
-
Debugging and Framework:
- We set the log level to
"ERROR"to minimize log output and specifytorchas the framework for training.
- We set the log level to
-
GPU Resources:
- The
.resources()call determines how many GPUs are used during training. Thenum_gpus=int(os.environ.get("RLLIB_NUM_GPUS", "0"))retrieves the number of available GPUs from the environment, but if no GPU is available, you can explicitly set this to0.
- The
-
Run PPO Training using
tune.run():tune.run("PPO"): This function launches the training process for the PPO algorithm.- Training name: The training job is named
"PPO"for easier tracking of results and logs. - Stopping Criteria: The training process stops once a total of
100,000 timestepsare completed (stop={"timesteps_total": 100000}). - Checkpointing: Model checkpoints are saved every 10 timesteps, allowing you to resume training later or analyze the model at different stages (
checkpoint_freq=10). - Storage Path: Training results and logs are stored in the directory specified (
storage_path="/define/your/path/ray_results/" + env_name). This is where you can track TensorBoard logs and other metrics.
Outcome
- With the PPO configuration and
tune.runset up, the training process is launched. The agents will start learning from their interactions with the environment, and progress will be saved periodically as checkpoints.
Evaluate Model Performance
Objective
- Test the trained PPO model and evaluate its effectiveness in managing traffic flow.
Step-by-Step Explanation
Once training is complete, it’s important to evaluate the PPO model’s performance by running it in the traffic simulation and comparing it with baseline methods or undertrained models.
-
Test the PPO Model
Run the trained PPO model in the same SUMO simulation and observe how it manages traffic compared to traditional fixed-timing signals or other models. -
Compare Metrics
Measure key metrics like total vehicle waiting time, average vehicle speed, and queue lengths at intersections. Compare these results with the performance of standard traffic light systems to assess the benefits of RL. -
Refine the Model
If the results aren’t optimal, consider adjusting the reward function, adding more traffic conditions to the simulation, or retraining the agents with different hyperparameters.
Outcome
By the end of this section, you’ll have a clear understanding of how well the PPO-trained agents are controlling traffic, and what improvements, if any, can be made.
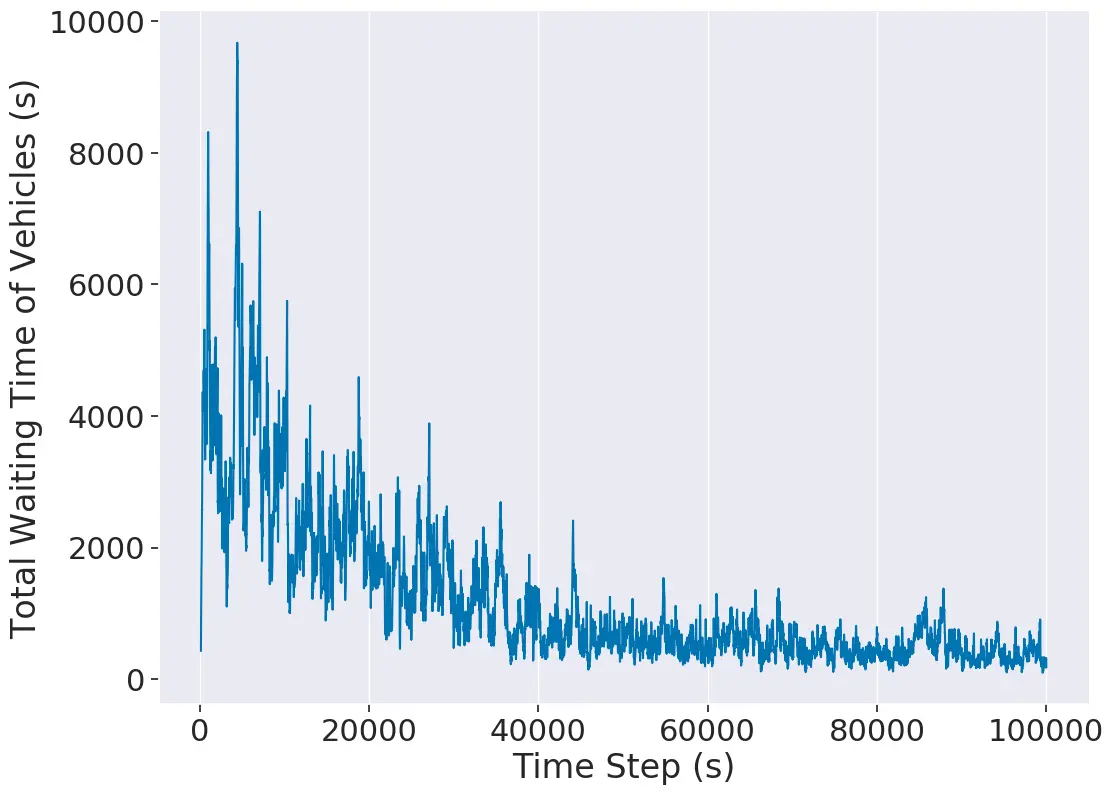
Plot The Data
- Using the given
plot.pyfile from the sumo-rl repo we can easily plot the data we get from our csv outputs.
# --- PLOT THE DATA ---
# Example 1
python outputs/plot.py -f outputs/4x4grid/ppo_conn0_ep42.csvExpected Result